one.ilmsg.in.th
- ⛪ Home
- 📚 book Think and Grow Rich
- 📚 book Rich Dad Poor Dad
- 📚 book The Power of Now
- 👻 book Getting Things Done (GTD)
- 👻 book Make Your Bed
- 🤖 book The 4-Hour Workweek
- 🤖 book Who Moved My Cheese?
- 🤖 book Deep Work
- 🤖 book How to Stop Worrying and Start Living
- 🤖 book Act Like a Lady, Think Like a Man
- 🤖 book The 7 Habits of Highly Effective People
- 😊 book Take back your time
- 🤖 book The 5 Second Rule
- 🤖 book The 5 Second Rule
- 🐕 book Data Structures & Algorithms Cheat Sheet
- 💬 book Chart Cheat Sheet
- 💬 book 8 Disciplines
- 💬 book Get Your Shit Together
- 💬 book Data Analyst
- 👻 book The $100 Startup
- 🕌 book 8 ข้อคิดจากหนังสือ The Startup Mindset
- 💬 book Disrupt Yourself
- 💬 book How to Read Any Room
- 💬 book Atomic Habits
- 💬 book หนังสือการเงิน 7 เล่ม
- 💬 book เคียร์เคอการ์ด ฉบับกระชับ
- 😺 book Startup Mindset
- 😊 idea (RBAC) in Next.js
- 😊 idea Concurrency in Go Web Applications
- 😊 idea best practices for multi tenant authorization
- 🎃 idea Your Money or Your Life
- 😊 idea Master The Art of Negotiation
- 😊 idea การรับมือกับความท้าทายในชีวิต
- 📌 idea Die With Zero
- 🎃 idea The Millionaire Fastlane
- 🤖 info How to learn anything 5x faster
- 🤖 tech Key Performance Indicators - KPIs
- 🤖 tech Frontend Performance Cheatsheet
- 🐡 tech Next.js ร่วมกับ gray-matter
- 📚 tech 6 Key Business Frameworks Matrix
- 📚 tech Chapter 01
- 😊 tech Concurrency in Go Web Applications
- 🐕 tech Essential Python Libraries for Data Science in 2025!
- 👋 tech Prompt Engineering Techniques
- 💨 tech TodoList ด้วย React, TypeScript, Firestore และ DaisyUI
- 🕌 tech The Ultimate API Learning Roadmap
- 👋 tech show me the cat
- 🐷 tech Running Lean
- 🦁 tech Cheatsheet On Database Performance
- 👻 tech Data Analytics
- 👻 tech Chapter 02
- 📌 tech One-Page Business Plan
- 🌟 tech วิธีทำน้ำอบไทย
Data Structures & Algorithms Cheat Sheet
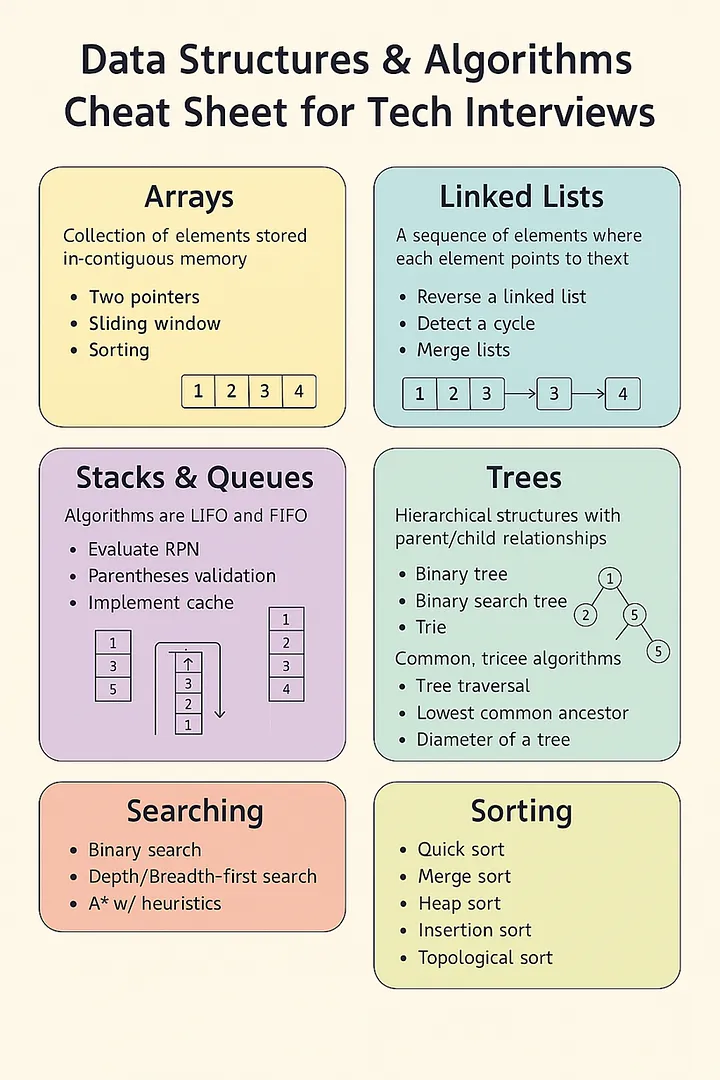
Data Structures & Algorithms Cheat Sheet for Tech Interviews
เอกสารสรุปนี้ครอบคลุมโครงสร้างข้อมูลและอัลกอริทึมพื้นฐานที่มักพบในการสัมภาษณ์งานด้านเทคโนโลยี แบ่งออกเป็นหกส่วนหลัก:
-
Arrays (อาร์เรย์):
- คำจำกัดความ: เป็นชุดขององค์ประกอบที่จัดเก็บในหน่วยความจำที่อยู่ติดกัน (contiguous memory) หมายความว่าข้อมูลแต่ละชิ้นจะถูกเก็บไว้เรียงต่อกันในหน่วยความจำ ทำให้เข้าถึงข้อมูลได้อย่างรวดเร็วโดยใช้ดัชนี (index)
- อัลกอริทึม/เทคนิคที่เกี่ยวข้อง:
- Two pointers: เทคนิคที่ใช้ตัวชี้ (pointer) สองตัวเคลื่อนที่ผ่านอาร์เรย์เพื่อแก้ปัญหาต่างๆ เช่น การหาคู่ที่รวมกันได้ค่าที่ต้องการ หรือการตรวจสอบพาลินโดรม
- Sliding window: เทคนิคที่ใช้ "หน้าต่าง" ขนาดคงที่หรือแปรผันเลื่อนไปตามอาร์เรย์เพื่อประมวลผลข้อมูลย่อยๆ มักใช้ในการหาค่าสูงสุด/ต่ำสุดในหน้าต่าง หรือหาลำดับย่อยที่ตรงตามเงื่อนไข
- Sorting: การจัดเรียงข้อมูลในอาร์เรย์ตามลำดับที่กำหนด (เช่น น้อยไปมาก หรือ มากไปน้อย) เป็นพื้นฐานสำคัญสำหรับอัลกอริทึมอื่นๆ
-
Linked Lists (ลิงก์ลิสต์):
- คำจำกัดความ: เป็นลำดับขององค์ประกอบ (เรียกว่า โหนด - node) ที่แต่ละโหนดจะมีการอ้างอิง (pointer) ชี้ไปยังโหนดถัดไป (หรือโหนดก่อนหน้าในกรณีของ Doubly Linked List) ข้อมูลไม่จำเป็นต้องเก็บในหน่วยความจำที่อยู่ติดกัน
- การดำเนินการที่เกี่ยวข้อง:
- Reverse a linked list: การกลับลำดับของโหนดในลิงก์ลิสต์
- Detect a cycle: การตรวจสอบว่ามีโหนดใดในลิงก์ลิสต์ที่ชี้กลับไปยังโหนดก่อนหน้า ทำให้เกิดเป็นวงจรหรือไม่
- Merge lists: การรวมลิงก์ลิสต์สองรายการ (หรือมากกว่า) เข้าด้วยกัน โดยมักจะเรียงลำดับข้อมูลไปด้วย
-
Stacks & Queues (สแต็กและคิว):
- คำจำกัดความ: เป็นโครงสร้างข้อมูลเชิงเส้นที่มีข้อจำกัดในการเพิ่มและลบข้อมูล
- Stack (สแต็ก): ทำงานแบบ LIFO (Last-In, First-Out) คือ ข้อมูลที่เข้ามาก่อนจะออกทีหลังสุด เหมือนกองจาน
- Queue (คิว): ทำงานแบบ FIFO (First-In, First-Out) คือ ข้อมูลที่เข้ามาก่อนจะออกก่อน เหมือนแถวรอคิว
- อัลกอริทึม/การประยุกต์ใช้:
- Evaluate RPN (Reverse Polish Notation): การคำนวณนิพจน์ทางคณิตศาสตร์ที่เขียนในรูปแบบ RPN โดยใช้สแต็ก
- Parentheses validation: การตรวจสอบว่าวงเล็บในนิพจน์เปิดและปิดถูกต้องตามลำดับหรือไม่ โดยใช้สแต็ก
- Implement cache: การสร้างแคช (เช่น LRU Cache - Least Recently Used) ซึ่งมักใช้คิวและโครงสร้างข้อมูลอื่นร่วมด้วย
- คำจำกัดความ: เป็นโครงสร้างข้อมูลเชิงเส้นที่มีข้อจำกัดในการเพิ่มและลบข้อมูล
-
Trees (ทรี):
- คำจำกัดความ: เป็นโครงสร้างข้อมูลแบบลำดับชั้น (hierarchical) ที่ประกอบด้วยโหนด (node) ที่มีความสัมพันธ์แบบพ่อ-ลูก (parent-child) โหนดบนสุดเรียกว่า ราก (root) และโหนดที่ไม่มีลูกเรียกว่า ใบ (leaf)
- ประเภทของทรี:
- Binary tree: ทรีที่แต่ละโหนดมีลูกได้ไม่เกินสองโหนด (ซ้ายและขวา)
- Binary search tree (BST): ทรีแบบไบนารีที่มีคุณสมบัติเพิ่มเติมคือ ค่าในโหนดลูกซ้ายทั้งหมดจะน้อยกว่าค่าในโหนดพ่อ และค่าในโหนดลูกขวาทั้งหมดจะมากกว่าค่าในโหนดพ่อ ทำให้ค้นหาข้อมูลได้เร็ว
- Trie (Prefix Tree): ทรีชนิดพิเศษที่ใช้เก็บและค้นหาสตริงตามคำนำหน้า (prefix) ได้อย่างมีประสิทธิภาพ
- อัลกอริทึมที่พบบ่อย:
- Tree traversal: การเยี่ยมชมโหนดทุกโหนดในทรีตามลำดับที่กำหนด (เช่น In-order, Pre-order, Post-order, Level-order)
- Lowest common ancestor (LCA): การหาโหนดบรรพบุรุษร่วมที่อยู่ต่ำที่สุด (ใกล้โหนดลูกที่สุด) ของโหนดสองโหนดที่กำหนดในทรี
- Diameter of a tree: การหาระยะทางที่ยาวที่สุดระหว่างโหนดสองโหนดใดๆ ในทรี
-
Searching (การค้นหา):
- คำจำกัดความ: เป็นกระบวนการในการหาตำแหน่งหรือการมีอยู่ของข้อมูลที่ต้องการในชุดข้อมูล
- อัลกอริทึมการค้นหา:
- Binary search: อัลกอริทึมการค้นหาที่มีประสิทธิภาพสูงสำหรับข้อมูลที่ เรียงลำดับแล้ว โดยแบ่งครึ่งช่วงการค้นหาไปเรื่อยๆ
- Depth-first search (DFS): การค้นหาในแนวลึก โดยจะสำรวจไปตามกิ่งก้านสาขาให้ลึกที่สุดก่อน แล้วจึงย้อนกลับมาสำรวจกิ่งอื่น มักใช้กับทรีและกราฟ
- Breadth-first search (BFS): การค้นหาในแนวกว้าง โดยจะสำรวจโหนดในระดับเดียวกันทั้งหมดก่อน แล้วจึงลงไปสำรวจระดับถัดไป มักใช้กับทรีและกราฟเพื่อหาระยะทางที่สั้นที่สุด
- A* w/ heuristics: อัลกอริทึมการค้นหาแบบมีข้อมูลนำทาง (informed search) ที่ใช้ฟังก์ชันฮิวริสติก (heuristic function) เพื่อประเมินค่าใช้จ่ายในการไปถึงเป้าหมาย ทำให้ค้นหาเส้นทางที่ดีที่สุดได้อย่างมีประสิทธิภาพ มักใช้ในการหาเส้นทางในกราฟ
-
Sorting (การเรียงลำดับ):
- คำจำกัดความ: เป็นกระบวนการจัดเรียงองค์ประกอบในชุดข้อมูลตามลำดับที่กำหนด (เช่น จากน้อยไปมาก หรือตามลำดับตัวอักษร)
- อัลกอริทึมการเรียงลำดับ:
- Quick sort: อัลกอริทึมแบบ Divide and Conquer ที่มีความเร็วเฉลี่ยสูง เลือก pivot แล้วแบ่งข้อมูลเป็นส่วนที่น้อยกว่าและมากกว่า pivot แล้วทำซ้ำ
- Merge sort: อัลกอริทึมแบบ Divide and Conquer ที่มีประสิทธิภาพคงที่ แบ่งข้อมูลเป็นส่วนย่อยๆ เรียงลำดับส่วนย่อย แล้วผสาน (merge) กลับเข้าด้วยกัน
- Heap sort: อัลกอริทึมที่ใช้โครงสร้างข้อมูลแบบ Heap (โดยเฉพาะ Binary Heap) ในการเรียงลำดับ
- Insertion sort: อัลกอริทึมอย่างง่ายที่ทำงานโดยค่อยๆ สร้างส่วนที่เรียงลำดับแล้วทีละองค์ประกอบ เหมาะสำหรับข้อมูลเกือบเรียงลำดับอยู่แล้วหรือชุดข้อมูลขนาดเล็ก
- Topological sort: การเรียงลำดับสำหรับ Directed Acyclic Graph (DAG) โดยจัดเรียงโหนดตามลำดับที่โหนดหนึ่งต้องมาก่อนอีกโหนดหนึ่งตามทิศทางของเส้นเชื่อม ใช้ในการจัดการลำดับงานที่ต้องทำก่อนหลัง
เอกสารสรุปนี้เป็นภาพรวมของหัวข้อสำคัญที่ควรเตรียมตัวสำหรับการสัมภาษณ์งานด้านเทคโนโลยี การทำความเข้าใจแนวคิดพื้นฐาน การทำงาน และความซับซ้อนทางเวลาและพื้นที่ (Time and Space Complexity) ของแต่ละโครงสร้างข้อมูลและอัลกอริทึมเหล่านี้เป็นสิ่งสำคัญอย่างยิ่ง