one.ilmsg.in.th
- ⛪ Home
- 📚 book Think and Grow Rich
- 📚 book Rich Dad Poor Dad
- 📚 book The Power of Now
- 👻 book Getting Things Done (GTD)
- 👻 book Make Your Bed
- 🤖 book The 4-Hour Workweek
- 🤖 book Who Moved My Cheese?
- 🤖 book Deep Work
- 🤖 book How to Stop Worrying and Start Living
- 🤖 book Act Like a Lady, Think Like a Man
- 🤖 book The 7 Habits of Highly Effective People
- 😊 book Take back your time
- 🤖 book The 5 Second Rule
- 🤖 book The 5 Second Rule
- 🐕 book Data Structures & Algorithms Cheat Sheet
- 💬 book Chart Cheat Sheet
- 💬 book 8 Disciplines
- 💬 book Get Your Shit Together
- 💬 book Data Analyst
- 👻 book The $100 Startup
- 🕌 book 8 ข้อคิดจากหนังสือ The Startup Mindset
- 💬 book Disrupt Yourself
- 💬 book How to Read Any Room
- 💬 book Atomic Habits
- 💬 book หนังสือการเงิน 7 เล่ม
- 💬 book เคียร์เคอการ์ด ฉบับกระชับ
- 😺 book Startup Mindset
- 😊 idea (RBAC) in Next.js
- 😊 idea Concurrency in Go Web Applications
- 😊 idea best practices for multi tenant authorization
- 🎃 idea Your Money or Your Life
- 😊 idea Master The Art of Negotiation
- 😊 idea การรับมือกับความท้าทายในชีวิต
- 📌 idea Die With Zero
- 🎃 idea The Millionaire Fastlane
- 🤖 info How to learn anything 5x faster
- 🤖 tech Key Performance Indicators - KPIs
- 🤖 tech Frontend Performance Cheatsheet
- 🐡 tech Next.js ร่วมกับ gray-matter
- 📚 tech 6 Key Business Frameworks Matrix
- 📚 tech Chapter 01
- 😊 tech Concurrency in Go Web Applications
- 🐕 tech Essential Python Libraries for Data Science in 2025!
- 👋 tech Prompt Engineering Techniques
- 💨 tech TodoList ด้วย React, TypeScript, Firestore และ DaisyUI
- 🕌 tech The Ultimate API Learning Roadmap
- 👋 tech show me the cat
- 🐷 tech Running Lean
- 🦁 tech Cheatsheet On Database Performance
- 👻 tech Data Analytics
- 👻 tech Chapter 02
- 📌 tech One-Page Business Plan
- 🌟 tech วิธีทำน้ำอบไทย
Data Analytics
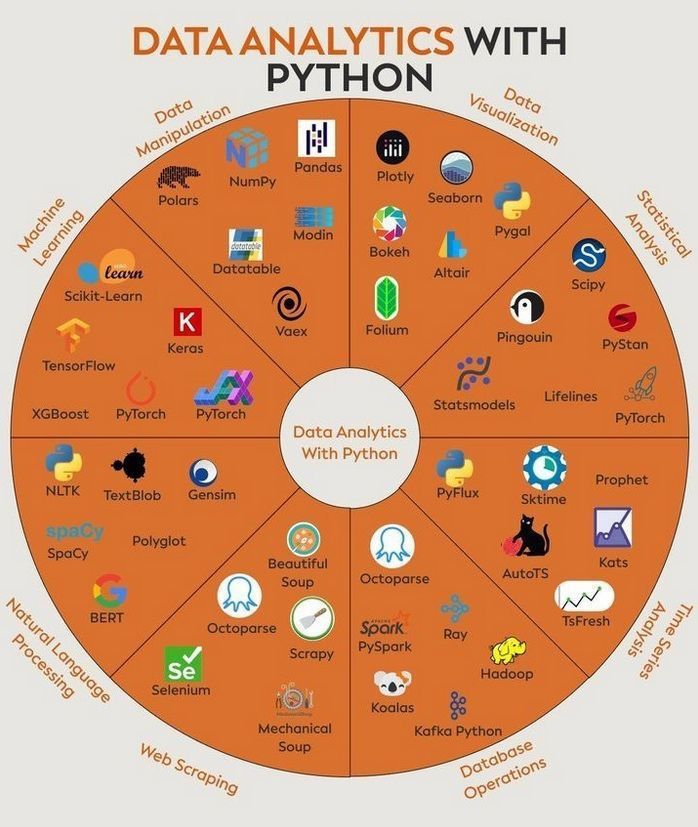
ภาพรวม: รูปภาพนี้แสดงไลบรารี Python ยอดนิยมต่างๆ ที่ใช้ในงานด้าน Data Analytics (การวิเคราะห์ข้อมูล) โดยแบ่งออกเป็นหมวดหมู่ตามลักษณะการใช้งาน ทำให้เห็นภาพรวมของเครื่องมือที่มีให้เลือกใช้ใน Python สำหรับงานข้อมูลประเภทต่างๆ
1. Data Manipulation (การจัดการข้อมูล)
- คำอธิบาย: หมวดหมู่นี้เกี่ยวข้องกับการเตรียมข้อมูล (Data Preparation) ซึ่งรวมถึงการทำความสะอาดข้อมูล (Cleaning), การแปลงข้อมูล (Transforming), การรวมข้อมูล (Merging), และการจัดรูปแบบข้อมูล (Reshaping) ให้อยู่ในรูปแบบที่เหมาะสมและพร้อมสำหรับการวิเคราะห์ในขั้นตอนต่อไป
- ไลบรารี:
- Polars: ไลบรารีใหม่ที่เน้นความเร็วสูงในการจัดการ DataFrame เขียนด้วย Rust ทำงานได้เร็วกว่า Pandas ในหลายกรณี
- NumPy (Numerical Python): ไลบรารีพื้นฐานสำคัญสำหรับการคำนวณทางวิทยาศาสตร์ใน Python โดยเฉพาะการทำงานกับอาร์เรย์ (Array) หลายมิติและเมทริกซ์ (Matrix)
- Pandas: ไลบรารียอดนิยมที่สุดสำหรับการจัดการข้อมูล มีโครงสร้างข้อมูลหลักคือ DataFrame (ตารางข้อมูล) และ Series (ข้อมูลคอลัมน์เดียว) ที่ใช้งานง่ายและมีฟังก์ชันหลากหลาย
- Modin: ช่วยเร่งความเร็วการทำงานของ Pandas โดยใช้การประมวลผลแบบขนาน (Parallel Processing) กับแกน CPU ทั้งหมด หรือแม้กระทั่งกับ Cluster โดยพยายามให้ใช้โค้ด Pandas เดิมได้เลย
- Datatable: ไลบรารีที่เน้นประสิทธิภาพในการอ่านและจัดการข้อมูลขนาดใหญ่ (โดยเฉพาะข้อมูลแบบตาราง) ได้อย่างรวดเร็ว ได้รับแรงบันดาลใจจาก data.table ในภาษา R
- Vaex: ออกแบบมาเพื่อทำงานกับชุดข้อมูลขนาดใหญ่มากๆ (Out-of-core) ที่มีขนาดใหญ่กว่าหน่วยความจำ (RAM) ของเครื่อง โดยใช้เทคนิค Memory Mapping และ Lazy Evaluation
- คำสั่งติดตั้ง:
(หมายเหตุ: Modin ต้องการ engine เสริมเช่น Ray หรือ Dask)pip install polars numpy pandas modin[ray] # หรือ modin[dask] datatable vaex - ตัวอย่าง (Pandas):
คำอธิบายโค้ด: สร้างตารางข้อมูลชื่อimport pandas as pd # สร้าง DataFrame (ตารางข้อมูล) อย่างง่าย data = {'ชื่อ': ['แก้ว', 'กล้า', 'ขวัญ'], 'อายุ': [25, 30, 22]} df = pd.DataFrame(data) # แสดง DataFrame print("DataFrame:") print(df) # เลือกดูเฉพาะคอลัมน์ 'อายุ' print("\nคอลัมน์ อายุ:") print(df['อายุ']) # คำนวณอายุเฉลี่ย print(f"\nอายุเฉลี่ย: {df['อายุ'].mean()}")dfที่มีคอลัมน์ 'ชื่อ' และ 'อายุ' จากนั้นแสดงตารางทั้งหมด, เลือกแสดงเฉพาะข้อมูลในคอลัมน์ 'อายุ', และคำนวณค่าเฉลี่ยของอายุ
2. Data Visualization (การแสดงผลข้อมูล)
- คำอธิบาย: การนำเสนอข้อมูลในรูปแบบภาพ เช่น กราฟ แผนภูมิ แผนภาพ เพื่อช่วยให้เข้าใจแนวโน้ม รูปแบบ ความสัมพันธ์ หรือข้อมูลเชิงลึก (Insights) ที่ซ่อนอยู่ในข้อมูลได้ง่ายและรวดเร็วยิ่งขึ้น
- ไลบรารี:
- Plotly: สร้างกราฟแบบโต้ตอบ (Interactive) และสวยงาม เหมาะสำหรับเว็บแอปพลิเคชันและแดชบอร์ด
- Seaborn: สร้างกราฟสถิติที่สวยงามและให้ข้อมูลเชิงลึกได้ดี ทำงานอยู่บน Matplotlib (ไลบรารีวาดกราฟพื้นฐาน) ทำให้ใช้ง่ายขึ้นสำหรับกราฟสถิติทั่วไป
- Pygal: สร้างกราฟแบบ SVG (Scalable Vector Graphics) ซึ่งคมชัดและสามารถโต้ตอบได้ในเบราว์เซอร์
- Bokeh: สร้างกราฟแบบโต้ตอบประสิทธิภาพสูงสำหรับเว็บเบราว์เซอร์สมัยใหม่ เหมาะสำหรับแดชบอร์ดและแอปพลิเคชันข้อมูล
- Altair: ไลบรารีการสร้างภาพข้อมูลแบบประกาศ (Declarative) ทำให้เขียนโค้ดสั้นกระชับเพื่อสร้างกราฟที่ซับซ้อนได้
- Folium: ใช้สร้างแผนที่แบบโต้ตอบ โดยใช้ความสามารถของไลบรารี Leaflet.js ทำให้ง่ายต่อการแสดงข้อมูลบนแผนที่
- คำสั่งติดตั้ง:
(หมายเหตุ: Seaborn และบางไลบรารีมักต้องใช้ Matplotlib เป็นเบื้องหลัง)pip install plotly seaborn pygal bokeh altair folium matplotlib - ตัวอย่าง (Seaborn):
import seaborn as sns import matplotlib.pyplot as plt # มักใช้ร่วมกับ seaborn เพื่อปรับแต่ง # Seaborn มีชุดข้อมูลตัวอย่างให้ใช้ tips = sns.load_dataset("tips") # แสดงข้อมูล 5 แถวแรก print(tips.head()) # สร้าง Scatter plot เพื่อดูความสัมพันธ์ระหว่าง 'total_bill' และ 'tip' sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time") # แยกสีตาม 'time' # แสดงกราฟ plt.title("ความสัมพันธ์ระหว่างยอดบิลทั้งหมดและทิป") plt.xlabel("ยอดบิลทั้งหมด (Total Bill)") plt.ylabel("ทิป (Tip)") plt.show() ``` **คำอธิบายโค้ด:** โหลดชุดข้อมูลตัวอย่าง `tips` จาก Seaborn จากนั้นใช้ `scatterplot` สร้างกราฟกระจายเพื่อดูว่ายอดบิลรวม (total_bill) สัมพันธ์กับจำนวนทิป (tip) อย่างไร โดยแยกสีของจุดตามช่วงเวลา (time) คือ Lunch หรือ Dinner
3. Statistical Analysis (การวิเคราะห์เชิงสถิติ)
- คำอธิบาย: การใช้เทคนิคและแบบจำลองทางสถิติเพื่อวิเคราะห์ข้อมูล ทำความเข้าใจความสัมพันธ์ ทดสอบสมมติฐาน และสร้างแบบจำลองเพื่ออธิบายหรือทำนายปรากฏการณ์ต่างๆ
- ไลบรารี:
- Scipy (Scientific Python): ส่วนต่อขยายของ NumPy มีฟังก์ชันทางคณิตศาสตร์ วิทยาศาสตร์ และวิศวกรรมขั้นสูง รวมถึงโมดูล
scipy.statsสำหรับการคำนวณทางสถิติต่างๆ เช่น การทดสอบสมมติฐาน การแจกแจงความน่าจะเป็น - PyStan: Interface สำหรับ Stan ซึ่งเป็นแพลตฟอร์มสำหรับการสร้างแบบจำลองทางสถิติและการอนุมานแบบเบย์ (Bayesian Inference) ประสิทธิภาพสูง
- Pingouin: ออกแบบมาเพื่อให้ทำการทดสอบทางสถิติทั่วไปได้ง่ายและรวดเร็ว ให้ผลลัพธ์ที่อ่านเข้าใจง่าย
- Statsmodels: เน้นการประมาณค่าแบบจำลองทางสถิติ การทดสอบทางสถิติ และการสำรวจข้อมูลทางสถิติ มีโมเดลหลากหลาย เช่น OLS (Linear Regression), ANOVA, Time Series Models (ARIMA)
- Lifelines: ใช้สำหรับการวิเคราะห์การอยู่รอด (Survival Analysis) ซึ่งเป็นการวิเคราะห์ระยะเวลาจนกว่าเหตุการณ์บางอย่างจะเกิดขึ้น
- PyTorch: แม้จะเป็นไลบรารี Deep Learning เป็นหลัก แต่ก็มีเครื่องมือพื้นฐานที่สามารถนำมาประยุกต์ใช้ในการคำนวณทางสถิติหรือสร้างแบบจำลองที่ซับซ้อนได้
- Scipy (Scientific Python): ส่วนต่อขยายของ NumPy มีฟังก์ชันทางคณิตศาสตร์ วิทยาศาสตร์ และวิศวกรรมขั้นสูง รวมถึงโมดูล
- คำสั่งติดตั้ง:
pip install scipy pystan pingouin statsmodels lifelines torch - ตัวอย่าง (Scipy):
คำอธิบายโค้ด: สร้างข้อมูลคะแนนสมมติ 2 กลุ่ม แล้วใช้ฟังก์ชันfrom scipy import stats import numpy as np # สมมติตัวอย่างคะแนนสอบของนักเรียน 2 กลุ่ม group1_scores = np.array([85, 90, 78, 92, 88]) group2_scores = np.array([75, 82, 80, 70, 79]) # ทำ Independent Samples t-test เพื่อทดสอบว่าคะแนนเฉลี่ยของ 2 กลุ่มต่างกันหรือไม่ t_statistic, p_value = stats.ttest_ind(group1_scores, group2_scores) print(f"T-statistic: {t_statistic:.4f}") print(f"P-value: {p_value:.4f}") # ตีความผล (ตัวอย่างง่ายๆ) alpha = 0.05 # ระดับนัยสำคัญ if p_value < alpha: print("ปฏิเสธสมมติฐานหลัก: คะแนนเฉลี่ยของสองกลุ่มแตกต่างกันอย่างมีนัยสำคัญ") else: print("ยอมรับสมมติฐานหลัก: ไม่มีหลักฐานเพียงพอว่าคะแนนเฉลี่ยของสองกลุ่มแตกต่างกัน")ttest_indจากscipy.statsเพื่อทดสอบว่าค่าเฉลี่ยของทั้งสองกลุ่มแตกต่างกันอย่างมีนัยสำคัญทางสถิติหรือไม่ โดยดูจากค่า p-value ที่ได้
4. Time Series Analysis (การวิเคราะห์อนุกรมเวลา)
- คำอธิบาย: การวิเคราะห์ข้อมูลที่ถูกเก็บรวบรวมตามลำดับเวลา เช่น ราคาหุ้นรายวัน ยอดขายรายเดือน อุณหภูมิรายชั่วโมง เพื่อหาแนวโน้ม รูปแบบตามฤดูกาล หรือพยากรณ์ค่าในอนาคต
- ไลบรารี:
- PyFlux: เน้นการสร้างแบบจำลองอนุกรมเวลาโดยใช้วิธีการแบบเบย์ (Bayesian methods)
- Sktime: เป็นเฟรมเวิร์กที่รวบรวมอัลกอริทึมสำหรับการเรียนรู้กับข้อมูลอนุกรมเวลา ทั้งการจำแนกประเภท การถดถอย และการพยากรณ์
- Prophet: พัฒนาโดย Facebook (Meta) ทำให้การพยากรณ์ข้อมูลอนุกรมเวลาที่มักมีรูปแบบตามฤดูกาล (Seasonality) และวันหยุด (Holidays) เป็นเรื่องง่าย
- AutoTS: พยายามหาแบบจำลองอนุกรมเวลาที่ดีที่สุดโดยอัตโนมัติจากชุดข้อมูลที่กำหนด
- Kats: พัฒนาโดย Facebook (Meta) เป็นเฟรมเวิร์กสำหรับวิเคราะห์ข้อมูลอนุกรมเวลา มีเครื่องมือหลากหลายตั้งแต่การตรวจจับความผิดปกติไปจนถึงการพยากรณ์
- TsFresh (Time Series Feature extraction based on scalable hypothesis tests): ใช้สำหรับสกัดคุณลักษณะ (Feature Extraction) จากข้อมูลอนุกรมเวลาโดยอัตโนมัติ ซึ่งมีประโยชน์ในการนำไปใช้กับโมเดล Machine Learning อื่นๆ
- คำสั่งติดตั้ง:
(หมายเหตุ: บางไลบรารีอาจมี dependency ที่ซับซ้อน โปรดดูเอกสารประกอบ)pip install pyflux sktime prophet autots kats tsfresh - ตัวอย่าง (Prophet):
คำอธิบายโค้ด: สร้าง DataFrame ที่มีคอลัมน์from prophet import Prophet import pandas as pd # สร้างข้อมูลตัวอย่าง (ต้องมีคอลัมน์ 'ds' สำหรับวันที่ และ 'y' สำหรับค่า) data = { 'ds': pd.to_datetime(['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04', '2023-01-05']), 'y': [10, 12, 15, 13, 16] } df = pd.DataFrame(data) print("ข้อมูลตัวอย่าง:") print(df) # สร้างและ fit โมเดล Prophet model = Prophet() model.fit(df) # สร้าง DataFrame สำหรับพยากรณ์อนาคต (เช่น 2 วันข้างหน้า) future = model.make_future_dataframe(periods=2) print("\nDataFrame สำหรับพยากรณ์:") print(future.tail()) # แสดงเฉพาะส่วนท้ายที่เป็นอนาคต # ทำการพยากรณ์ forecast = model.predict(future) # แสดงผลการพยากรณ์ (เฉพาะส่วนที่สำคัญ) print("\nผลการพยากรณ์:") print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail())ds(วันที่) และy(ค่าที่ต้องการพยากรณ์) จากนั้นสร้างโมเดล Prophet, สอนโมเดลด้วยข้อมูล (fit), สร้างกรอบเวลาสำหรับอนาคต, และใช้โมเดลทำนายค่า (predict) พร้อมแสดงค่าพยากรณ์ (yhat) และช่วงความเชื่อมั่น (yhat_lower,yhat_upper)
5. Database Operations (การดำเนินการกับฐานข้อมูล)
- คำอธิบาย: การเชื่อมต่อ อ่าน เขียน และจัดการข้อมูลที่เก็บอยู่ในระบบฐานข้อมูลต่างๆ (เช่น SQL, NoSQL) หรือระบบประมวลผลข้อมูลขนาดใหญ่แบบกระจาย (Distributed Systems)
- ไลบรารี:
- Octoparse: (ปรากฏใน Web Scraping ด้วย) เป็นเครื่องมือ/บริการสำหรับการดึงข้อมูลจากเว็บ ซึ่งอาจมีฟีเจอร์ในการส่งออกข้อมูลไปยังฐานข้อมูล แต่ไม่ใช่ไลบรารี Python โดยตรงสำหรับการดำเนินการกับฐานข้อมูลทั่วไป
- Spark / PySpark: Apache Spark เป็นเอนจิ้นประมวลผลข้อมูลขนาดใหญ่แบบกระจายที่รวดเร็ว PySpark คือ Python API สำหรับ Spark ทำให้สามารถเขียนโค้ด Python เพื่อทำงานบน Spark Cluster ได้
- Ray: เฟรมเวิร์กสำหรับสร้างแอปพลิเคชันแบบกระจาย (Distributed Applications) สามารถใช้เร่งความเร็วการประมวลผลข้อมูลและ Machine Learning ได้
- Hadoop: ระบบนิเวศสำหรับการจัดเก็บและประมวลผลข้อมูลขนาดใหญ่ (Big Data) แบบกระจาย การทำงานกับ Hadoop จาก Python มักใช้ไลบรารีอื่น เช่น
hdfs(สำหรับ HDFS),PyArrow(สำหรับไฟล์ฟอร์แมตต่างๆ) หรือผ่าน PySpark - Koalas: (ปัจจุบันรวมเข้าเป็นส่วนหนึ่งของ PySpark ในชื่อ
pyspark.pandas) มี API ที่คล้ายกับ Pandas แต่ทำงานบน Apache Spark ทำให้ง่ายสำหรับคนที่คุ้นเคยกับ Pandas ในการทำงานกับข้อมูลขนาดใหญ่บน Spark - Kafka Python: ไลบรารี Client สำหรับเชื่อมต่อและโต้ตอบกับ Apache Kafka ซึ่งเป็นแพลตฟอร์ม Streaming ข้อมูลแบบกระจาย
- คำสั่งติดตั้ง:
(หมายเหตุ: การใช้ PySpark, Ray, Hadoop, Kafka มักต้องมีการติดตั้งและตั้งค่าระบบพื้นฐานเหล่านั้นแยกต่างหาก Octoparse เป็นเครื่องมือ/บริการ ไม่ใช่ไลบรารี pip install โดยตรง)pip install pyspark ray kafka-python pandas # pyspark.pandas มาพร้อม pyspark >= 3.2 # pip install hdfs pyarrow # สำหรับ Hadoop/HDFS โดยตรง (อาจต้องการการตั้งค่าเพิ่มเติม) - ตัวอย่าง (PySpark):
คำอธิบายโค้ด: สร้างfrom pyspark.sql import SparkSession import pandas as pd # สร้าง SparkSession (จุดเริ่มต้นการทำงานกับ Spark) # .master("local[*]") หมายถึงให้ทำงานบนเครื่อง local โดยใช้ core ทั้งหมด spark = SparkSession.builder.appName("SimplePySparkExample").master("local[*]").getOrCreate() # สร้าง PySpark DataFrame จาก Pandas DataFrame (ตัวอย่างง่ายๆ) pandas_df = pd.DataFrame({'col1': [1, 2, 3], 'col2': ['A', 'B', 'C']}) spark_df = spark.createDataFrame(pandas_df) print("PySpark DataFrame:") spark_df.show() # แสดง DataFrame # ทำการ Query ง่ายๆ print("\nผลลัพธ์หลัง Filter:") spark_df.filter(spark_df.col1 > 1).show() # หยุด SparkSession spark.stop()SparkSessionเพื่อเริ่มการทำงานกับ Spark จากนั้นแปลง Pandas DataFrame เป็น PySpark DataFrame แล้วแสดงผล และทดลองกรองข้อมูล (filter) ก่อนจะหยุดSparkSession(จำเป็นต้องติดตั้ง Spark ในเครื่อง หรือเชื่อมต่อกับ Cluster)
6. Web Scraping (การดึงข้อมูลจากเว็บ)
- คำอธิบาย: กระบวนการดึงข้อมูล (Extract) จากหน้าเว็บไซต์ต่างๆ โดยอัตโนมัติ เพื่อนำข้อมูลเหล่านั้นมาใช้งานต่อ เช่น วิเคราะห์ราคา เก็บข้อมูลสินค้า หรือรวบรวมข่าวสาร
- ไลบรารี:
- Beautiful Soup: ไลบรารียอดนิยมสำหรับการแยก (Parse) ข้อมูลออกจากไฟล์ HTML และ XML ใช้งานง่าย เหมาะกับการดึงข้อมูลจากโครงสร้างหน้าเว็บที่ไม่ซับซ้อนมากนัก มักใช้ร่วมกับ
requestsเพื่อดาวน์โหลดหน้าเว็บก่อน - Octoparse: เป็นเครื่องมือ/ซอฟต์แวร์ (มีทั้งแบบติดตั้งและแบบคลาวด์) ที่ช่วยให้ดึงข้อมูลจากเว็บได้ง่ายขึ้นผ่าน Interface แบบกราฟิก อาจไม่ต้องเขียนโค้ดมากนัก
- Scrapy: เฟรมเวิร์ก (Framework) สำหรับ Web Scraping และ Web Crawling ที่มีประสิทธิภาพสูงและยืดหยุ่น เหมาะสำหรับโปรเจกต์ขนาดใหญ่และซับซ้อน สามารถจัดการ Request/Response, การวนซ้ำตามลิงก์, การจัดเก็บข้อมูลได้เป็นระบบ
- Mechanical Soup: สร้างขึ้นบน
requestsและBeautiful Soupเพื่อจำลองการโต้ตอบกับเว็บไซต์ได้ง่ายขึ้น เช่น การกรอกฟอร์ม การคลิกปุ่ม โดยไม่ต้องใช้เบราว์เซอร์จริง - Selenium: ใช้ควบคุมเว็บเบราว์เซอร์ (เช่น Chrome, Firefox) โดยอัตโนมัติ เหมาะสำหรับเว็บที่มีการใช้ JavaScript เยอะๆ หรือต้องการจำลองพฤติกรรมผู้ใช้จริง เช่น การคลิก การเลื่อนหน้าจอ แต่จะทำงานช้ากว่าวิธีอื่นเพราะต้องรันเบราว์เซอร์จริง
- Beautiful Soup: ไลบรารียอดนิยมสำหรับการแยก (Parse) ข้อมูลออกจากไฟล์ HTML และ XML ใช้งานง่าย เหมาะกับการดึงข้อมูลจากโครงสร้างหน้าเว็บที่ไม่ซับซ้อนมากนัก มักใช้ร่วมกับ
- คำสั่งติดตั้ง:
(หมายเหตุ: Selenium ต้องดาวน์โหลด WebDriver สำหรับเบราว์เซอร์ที่ต้องการควบคุมแยกต่างหาก Octoparse เป็นเครื่องมือ/บริการ)pip install beautifulsoup4 requests scrapy mechanicalsoup selenium - ตัวอย่าง (Beautiful Soup + Requests):
คำอธิบายโค้ด: ใช้import requests from bs4 import BeautifulSoup # URL ของเว็บที่ต้องการดึงข้อมูล (ตัวอย่างเว็บทดสอบง่ายๆ) url = 'http://example.com/' try: # ส่ง HTTP GET request เพื่อดาวน์โหลดเนื้อหาเว็บ response = requests.get(url) response.raise_for_status() # ตรวจสอบว่า request สำเร็จหรือไม่ # ใช้ BeautifulSoup แยกโครงสร้าง HTML soup = BeautifulSoup(response.text, 'html.parser') # ค้นหา tag ที่ต้องการ (เช่น tag <title>) title_tag = soup.find('title') if title_tag: print(f"Title ของเว็บ: {title_tag.string}") else: print("ไม่พบ tag <title>") # ค้นหา tag <p> แรก first_paragraph = soup.find('p') if first_paragraph: print(f"Paragraph แรก: {first_paragraph.get_text()}") # .get_text() เพื่อเอาเฉพาะข้อความ else: print("ไม่พบ tag <p>") except requests.exceptions.RequestException as e: print(f"เกิดข้อผิดพลาดในการเชื่อมต่อ: {e}")requestsเพื่อดาวน์โหลดเนื้อหา HTML จาก URL ที่กำหนด จากนั้นใช้BeautifulSoupเพื่อแยกวิเคราะห์ HTML นั้น แล้วค้นหาแท็ก<title>และแท็ก<p>แรก เพื่อดึงข้อความออกมาแสดงผล
7. Natural Language Processing (NLP) (การประมวลผลภาษาธรรมชาติ)
- คำอธิบาย: สาขาที่เกี่ยวข้องกับการทำให้คอมพิวเตอร์สามารถเข้าใจ ตีความ และประมวลผลภาษามนุษย์ได้ (ทั้งข้อความและเสียงพูด) เช่น การแปลภาษา การวิเคราะห์ความรู้สึก การสรุปความ การสร้างข้อความ
- ไลบรารี:
- NLTK (Natural Language Toolkit): ไลบรารีเก่าแก่และครอบคลุม มีเครื่องมือหลากหลายสำหรับการวิจัยและการเรียนรู้ NLP เช่น การตัดคำ (Tokenization), การระบุชนิดคำ (Part-of-Speech Tagging), การวิเคราะห์โครงสร้างประโยค (Parsing)
- TextBlob: สร้างบน NLTK และ Pattern ทำให้มี API ที่ใช้ง่ายสำหรับงาน NLP ทั่วไป เช่น การวิเคราะห์ความรู้สึก (Sentiment Analysis), การแยกวลี (Noun Phrase Extraction)
- Gensim: เน้นการทำ Topic Modeling (เช่น LDA), Document Similarity (การหาความคล้ายคลึงของเอกสาร) และ Word Embeddings (เช่น Word2Vec)
- spaCy: ออกแบบมาเพื่อประสิทธิภาพและความสะดวกในการใช้งานในระดับ Production เน้นความเร็วและความแม่นยำในงานพื้นฐาน เช่น Tokenization, POS Tagging, Named Entity Recognition (NER), Dependency Parsing
- Polyglot: รองรับงาน NLP สำหรับภาษาต่างๆ จำนวนมาก มีฟังก์ชันคล้าย NLTK และ spaCy แต่เน้นความสามารถด้านพหุภาษา (Multilingual)
- BERT (Bidirectional Encoder Representations from Transformers): เป็นโมเดลภาษาขนาดใหญ่ที่ทันสมัย พัฒนาโดย Google ไม่ใช่ไลบรารีโดยตรง แต่เป็นโมเดลที่มักถูกนำมาใช้งานผ่านไลบรารีอื่น เช่น
Transformers(จาก Hugging Face), TensorFlow, หรือ PyTorch เพื่อทำงาน NLP ที่ซับซ้อนและได้ผลลัพธ์แม่นยำสูง
- คำสั่งติดตั้ง:
pip install nltk textblob gensim spacy polyglot transformers torch # หรือ tensorflow # ต้องดาวน์โหลดโมเดลภาษาสำหรับ spaCy และ NLTK เพิ่มเติม # python -m spacy download en_core_web_sm # ตัวอย่างดาวน์โหลดโมเดลภาษาอังกฤษสำหรับ spaCy # python -m nltk.downloader punkt # ตัวอย่างดาวน์โหลดข้อมูลสำหรับ NLTK - ตัวอย่าง (spaCy):
คำอธิบายโค้ด: โหลดโมเดลภาษาอังกฤษของ spaCy จากนั้นนำไปประมวลผล (import spacy # โหลดโมเดลภาษาอังกฤษขนาดเล็ก (ต้องดาวน์โหลดก่อน: python -m spacy download en_core_web_sm) try: nlp = spacy.load("en_core_web_sm") except OSError: print("กรุณาดาวน์โหลดโมเดลภาษาก่อน: python -m spacy download en_core_web_sm") exit() # ข้อความตัวอย่าง text = "Apple is looking at buying U.K. startup for $1 billion." # ประมวลผลข้อความด้วย spaCy doc = nlp(text) print(f"ข้อความ: {text}") # แสดง Token และ Part-of-Speech (POS) tag print("\nTokens และ POS tags:") for token in doc: print(f"- {token.text} ({token.pos_})") # แสดงคำ และ ชนิดของคำ # แสดง Named Entities (NER) ที่ระบุได้ print("\nNamed Entities:") for ent in doc.ents: print(f"- {ent.text} ({ent.label_})") # แสดง entity และ ประเภท (เช่น ORG=องค์กร, GPE=สถานที่)nlp(text)) ประโยคตัวอย่าง ผลลัพธ์docจะเก็บข้อมูลการวิเคราะห์ต่างๆ เช่น การตัดคำ (Token), ชนิดของคำ (POS), และการระบุชื่อเฉพาะ (NER) แล้วนำข้อมูลเหล่านี้มาแสดงผล
8. Machine Learning (ML) (การเรียนรู้ของเครื่อง)
- คำอธิบาย: สาขาหนึ่งของปัญญาประดิษฐ์ (AI) ที่เน้นการสร้างระบบหรือโมเดลที่สามารถเรียนรู้รูปแบบจากข้อมูลได้ด้วยตนเอง และนำความรู้นั้นไปใช้ในการตัดสินใจ ทำนาย หรือจำแนกประเภทข้อมูลใหม่ที่ไม่เคยเห็นมาก่อน
- ไลบรารี:
- Scikit-Learn: ไลบรารี ML ที่ครอบคลุมและใช้งานง่ายที่สุดสำหรับงาน ML แบบคลาสสิก มีอัลกอริทึมหลากหลายทั้ง Supervised Learning (เช่น Regression, Classification) และ Unsupervised Learning (เช่น Clustering, Dimensionality Reduction) พร้อมเครื่องมือประเมินผลโมเดลและเตรียมข้อมูล
- Keras: High-level API สำหรับ Neural Networks ทำให้การสร้าง ทดสอบ และใช้งานโมเดล Deep Learning ง่ายขึ้น สามารถทำงานบน Backend อื่นๆ ได้ เช่น TensorFlow, Theano (เก่า), CNTK (ปัจจุบันนิยมใช้บน TensorFlow มากที่สุด)
- TensorFlow: พัฒนาโดย Google เป็นแพลตฟอร์ม End-to-end สำหรับ Machine Learning และ Deep Learning ที่มีประสิทธิภาพสูง ยืดหยุ่น และรองรับการนำโมเดลไปใช้งาน (Deployment) ในหลายสภาพแวดล้อม
- XGBoost: ไลบรารีที่ได้รับความนิยมสูงสำหรับการทำ Gradient Boosting ซึ่งเป็นเทคนิค Ensemble ที่มักให้ผลลัพธ์แม่นยำในการแข่งขัน Kaggle และงานด้าน Tabular Data
- PyTorch: พัฒนาโดย Facebook (Meta) เป็นอีกหนึ่งแพลตฟอร์ม Deep Learning ชั้นนำ คู่แข่งสำคัญของ TensorFlow มีความยืดหยุ่นสูง (นิยมในงานวิจัย) และมี Ecosystem ที่เติบโตอย่างรวดเร็ว
- คำสั่งติดตั้ง:
pip install scikit-learn keras tensorflow xgboost torch - ตัวอย่าง (Scikit-Learn):
คำอธิบายโค้ด: สร้างข้อมูลตัวอย่างสำหรับปัญหา Linear Regression แบ่งข้อมูลเป็นชุดสำหรับสอน (Train) และทดสอบ (Test) สร้างโมเดลfrom sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.datasets import make_regression # สร้างข้อมูลตัวอย่างสำหรับการถดถอย from sklearn.metrics import mean_squared_error # 1. สร้างข้อมูลตัวอย่าง # สร้างข้อมูล X (features) 100 ตัวอย่าง, 1 feature และ y (target) ที่มีความสัมพันธ์เชิงเส้น + noise X, y = make_regression(n_samples=100, n_features=1, noise=10, random_state=42) # 2. แบ่งข้อมูลเป็นชุด Train และ Test X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # test_size=0.2 คือแบ่งข้อมูลทดสอบ 20% # 3. สร้างและสอนโมเดล Linear Regression model = LinearRegression() model.fit(X_train, y_train) # สอนโมเดลด้วยข้อมูล Train # 4. ทำนายข้อมูล Test y_pred = model.predict(X_test) # 5. ประเมินผลโมเดล mse = mean_squared_error(y_test, y_pred) print(f"ข้อมูลตัวอย่าง X_test 5 ค่าแรก:\n{X_test[:5].flatten()}") print(f"ค่าจริง y_test 5 ค่าแรก:\n{y_test[:5]}") print(f"ค่าทำนาย y_pred 5 ค่าแรก:\n{y_pred[:5]}") print(f"\nMean Squared Error (MSE) บน Test set: {mse:.4f}") # ค่า error ยิ่งน้อยยิ่งดี print(f"ค่าสัมประสิทธิ์ (Coefficient): {model.coef_[0]:.4f}") # ความชัน print(f"ค่าจุดตัดแกน (Intercept): {model.intercept_:.4f}") # จุดตัดแกน yLinearRegressionสอนโมเดลด้วยข้อมูล Train (fit) นำโมเดลไปทำนายค่าสำหรับข้อมูล Test (predict) และสุดท้ายประเมินผลด้วย Mean Squared Error เพื่อดูว่าโมเดลทำนายได้ใกล้เคียงค่าจริงแค่ไหน
หวังว่าคำอธิบายเหล่านี้จะเป็นประโยชน์นะครับ! Python มีเครื่องมือที่ทรงพลังมากมายสำหรับงานด้านข้อมูลจริงๆ ครับ